


编者按:为深入学习贯彻党的二十届四中全会精神,更好服务“十五五”发展目标和金融强国建设,促进衍生品业务稳步发展,中证报价投教基地推出“风险管理工具系列”专题,聚焦场外衍生品在提供适配长期投资的风险管理工具、服务实体经济发展中的功能作用,展现其在助力经济社会高质量发展中的实践路径与创新成果。
作者:广发证券股份有限公司股权衍生品业务部和稽核部课题组
本文基于人工智能在场外衍生品领域的应用实践,系统分析了AI技术在模型可靠性、策略趋同、黑箱问题、数据隐私、大模型特有安全风险等方面带来的新挑战,并提出相应的风险应对与治理建议。在模型应用难点方面,文章指出AI的随机性与幻觉问题对场外衍生品定价与风险管理构成重大风险,建议通过组件分离、提示工程、人机协同、分级应用等手段提升模型的可靠性与可复现性。同时,强调从数据治理、持续学习与混合建模等方面应对AI幻觉。针对策略趋同放大波动的风险,建议通过算法报备、交易监控提升市场透明度,并通过数据与模型多样性激励降低同质化风险。在黑箱问题方面,提出引入可解释AI技术(如SHAP、LIME、反事实推理)和构建全生命周期模型治理框架,以增强模型透明度与可审计性。关于客户隐私数据保护,建议实施本地化部署、信息隔离、动态权限控制与隐私增强技术,构建纵深防御体系,确保数据安全与合规。针对AI大模型特有安全风险,如提示注入、模型攻击与服务中断,提出构建多层动态防御、模型资产分级加密与弹性服务架构等措施。最后,文章结合境内外监管立法趋势,提出建立分类分级监管框架,强调在智能客服等标准化领域优先试点,在核心业务领域坚持“试点先行、逐步深化”的原则,确保技术创新与风险控制的动态平衡。
模型应用主要难点的应对
随着人工智能技术,特别是生成式AI(GenAI),在场外衍生品运营、客户服务、定价、风险评估和交易策略中的应用日益深入,其模型应用的难点也带来了新的挑战。与传统量化模型相比,AI模型,尤其是深度学习模型,因其高度非线性和对训练数据分布的敏感性,更易在市场环境发生结构性变化时出现性能衰减与输出不稳定。
当前业界的痛点集中体现在:其一,AI内在的随机性(Non-determinism)导致模型输出难以完全复现,严重影响了在场外衍生品领域应用的可靠性、一致性及审计追踪;其二,“AI幻觉”(AI Hallucination)会生成看似合理但实则错误的定价或风险信息。这既可能源于错误或不可靠的训练数据对模型的误导,也可能源于市场环境、监管政策或行业实践的突发性变化,导致实际场景与训练数据分布产生显著差异,进而引发模型在适应过程中出现性能退化与知识遗忘。这些挑战对于结构复杂、流动性较差且缺乏权威定价基准的场外衍生品而言,潜在风险尤为巨大。
针对上述痛点,目前的应对思路正从单纯追求模型精度转向可靠性(Reliability)与可复现性(Reproducibility)并重,主要方法包括通过技术手段剥离并控制模型中的随机组件、采用联邦学习等隐私计算技术构建高质量数据基座以从源头减少幻觉,以及建立分级的模型风险管理框架,审慎地将AI的非确定性纳入应用场景的考量之中。
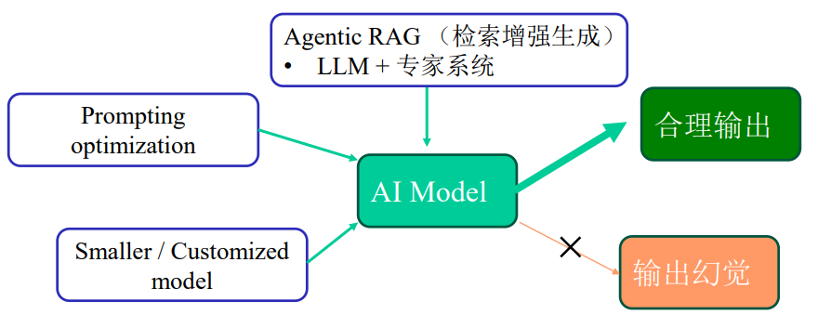
▍AI内在随机性的应对
在人工智能技术的应用过程中,随机性是其内在特性之一,尤其在使用生成式模型和概率性推理方法时更为显著。为提升AI系统在场外衍生品等金融场景中的可靠性与一致性,可通过组件分离、控制增强和场景分级等方式对随机性进行约束与管理。例如,在模型推理阶段关闭随机层、固定随机种子,通过提示词工程约束输出空间,以及依据业务重要性对应用场景实施分级治理,从而在特定领域中降低随机性带来的不确定性风险。
然而,随机性控制与模型性能之间存在天然的张力。当施加过多确定性约束时,AI系统可能退化为近似规则引擎或传统数值模型,不仅丧失其处理高维非线性问题的能力,也可能削弱其泛化性和创新性。过度追求确定性输出将削弱AI相对于传统方法在处理复杂场外衍生品方面的优势。
因此,应对AI内在随机性的核心并非追求完全消除不确定性,而是在“可控随机”与“生成多样性”之间寻求平衡。一个良好的AI系统应在保证输出合理性与稳健性的前提下,保留一定的探索和生成能力,从而在合规与创新、确定性与灵活性之间取得科学平衡。这既是技术挑战,也涉及算法伦理和治理哲学的深入思考。以下为常用的应对AI内在随机性的措施:
1、降低内在随机性,提升模型可复现性。
实施组件分离与确定性推理,分离GenAI组件,分析确定GenAI系统中导致非确定性产生的组件,在对输出结果确定性要求较高的场外衍生品应用场景中,关闭相关带有随机性的组件,确保模型在推理结果的一致性。
例如,在场外衍生品履约保障业务中,对于履约文本的分析、对客户推送追保通知、解答客户在履约保障方面的疑问等场景下,可以使用较为完整GenAI,提高工作效率。但在盯市、追保金额计算等场景,则可以禁用模型中的随机层,确保生成结果稳定、可复现。此外,建立环境一致性管理体系,封装模型及其所有依赖库,确保从研发到生产的环境完全一致,也能有效避免因环境差异导致结果偏差。
2、通过流程优化与控制机制约束随机性
一是通过提示词工程引导生成式人工智能产生稳定的输出结果。通过提供上下文、示例和明确格式,可以缩小模型的输出空间,从而降低随机性。例如,可为利率互换产品估值任务设计结构化提示模板,明确要求模型按“贴现曲线构建→浮动端现金流预测→固定端现值计算→利差调整”等多步骤输出估值过程及中间结果,避免模型自由发挥导致的计算逻辑不一致
二是构建人机协同与多层校验机制。在关键决策环节引入人工监督,构建“人在环中”(Human-in-the-Loop)的混合决策体系。以建立三级校验机制为例:首层为系统自动校验(主要对逻辑一致性、数值合理性进行检测);第二层为交叉验证(与传统模型或市场一致性检验对比);第三层为专家复核,尤其针对高风险或低置信度输出。
例如可建立适用于场外衍生品业务的三级校验机制:首层为系统自动校验,包括逻辑一致性(如期权价格正负值是否与对应期权品种一致)、数值合理性(如希腊值是否在理论范围内)等;第二层为交叉验证,将AI输出与传统定价模型(如Black-Scholes模型)、市场共识价格或历史交易数据进行比对,识别显著偏差;第三层为专家复核,尤其针对复杂衍生品(如雪球期权、累计期权等)或低置信度输出,由资深交易员或风控专家进行最终审定。例如,在障碍期权定价AI应用中设置自动预警阈值,当模型输出与蒙特卡罗模拟结果差异超过2%时,自动触发人工复核流程。
三是实施输入输出约束。在前端通过业务规则引擎限制用户输入,在后端对输出格式和数值范围进行强制约束,例如,对于期权产品,可事先强制要求模型输出价格为正、Delta绝对值不大于1;对于波动率曲面生成任务,约束不同期限与行权价之间的波动率值需满足单调性和平滑性要求。此外,对可嵌入各类衍生品特有的边界条件进行设定(如奇异期权的最差收益底线、信用衍生品的最大损失上限等),确保输出结果始终处于业务可接受范围内。
行业内目前也有通过流程优化与控制机制约束随机性的实践案例。浦发银行通过“大模型+向量数据库”搭建审计领域的制度搜索服务,在向量数据库中构建自有审计制度知识资产,并进行提示工程采用对话引导式问答交互,通过问答形式完成知识查找。
在数据准备阶段,浦发银行准备了数百篇审计知识文档以及审计专家积累的高质量审计问答。为降低内在随机性的影响,浦发银行采用“大模型+小模型”两路召回的方案实现。用户进行问答交互时,提问问题一方面会通过AI“大模型”进行结果输出,另一方面会通过“小模型”对问题进行精准切割,生成约束性的提示词召回至向量数据库中,精准匹配向量数据库中的标准化内容。最后输出既包含大模型创造性内容,又包含小模型匹配后精准化专业内容的混合回答。通过上述“大语言模型+向量数据库”架构,提示词工程引导生成过程,结合传统检索模型形成混合输出,既发挥了大模型的语义理解优势,又通过确定性检索成分约束生成随机性,提升专业问答的准确性与可靠性。
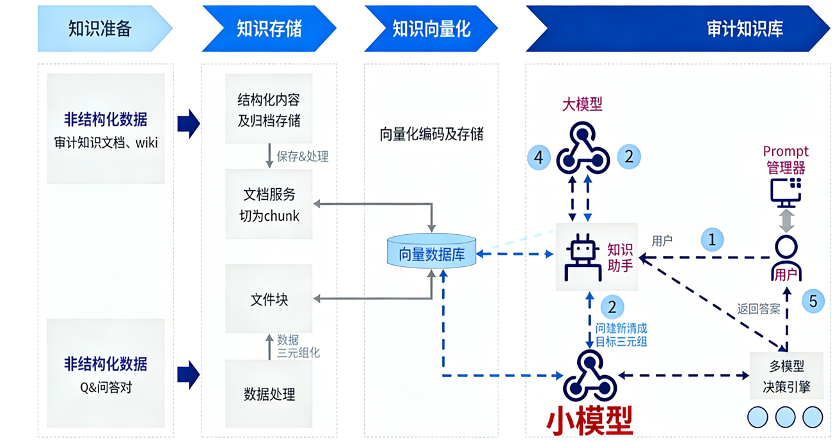
图:浦发银行审计知识库问答场景大模型应用
3、分级应用与风险适配策略
人工智能由于对LLM等模型的使用,导致内在随机性不可避免,某些情况下,人工智能的输出结果只能是一种期望范围,而不是一个固定的值。然而不同金融应用场景对错误的容忍度存在差异,需要根据决策的重要性、实时性要求和潜在损失影响来配置相应的技术方案,实现风险收益的最优匹配。高置信度输出可自动化处理,低置信度输出则需触发复核流程,这是构建可信人工智能系统的关键。
例如在场外衍生品业务领域建立应用场景分级体系,将应用场景分为低容忍度、中容忍度和高容忍度三个等级。低容忍度场景包括正式估值报送、监管资本计算和交易清算,必须使用完全确定性的模型;中容忍度场景包括内部风险管理和交易员询价参考,可使用带有随机性的人工智能模型,但必须附加置信度评分;高容忍度场景包括客户咨询服务、市场宏观分析和培训材料准备,可以充分发挥生成式人工智能的创造性,但内容需经过合规审核。其次,实施置信度披露与降级机制。为人工智能模型的输出实时计算置信度分数,当置信度低于设定阈值时,系统应自动切换至备用方案或提示人工审批。
▍AI幻觉的应对
AI幻觉指模型生成看似合理但实则错误或虚构的输出,其在金融衍生品等高精度要求领域可能引发重大估值偏离与风险误判。该问题源于训练数据缺陷、模型结构特性及外部环境突变等多重因素。应对AI幻觉需从数据治理、模型优化及机制设计等三个维度系统性地提升模型的真实性与稳健性。
1、提升训练数据的可靠性,提升模型反欺诈能力
①通过行业共享等方式,提升模型的反欺诈能力。印度ICICI银行建立“联邦学习联盟”,联合20家区域性银行在不共享原始数据的前提下,共同训练反欺诈模型。通过Tensor Flow Federated框架,各机构仅上传模型更新梯度,确保客户交易数据不出本地,模型在跨机构测试中对跨银行欺诈的识别率提升58%。在我国场外衍生品领域,可探索由行业协会或监管机构牵头,构建场外衍生品可信数据共享平台,对于不涉及数据隐私的数据进行行业共享,保障输入数据的可靠性;对于涉及数据隐私的数据,则是行业在不共享原始数据的前提下,共同训练反欺诈模型,各机构仅上传模型更新梯度,完成训练的反欺诈模型行业共享,以此提升模型反欺诈能力。
②通过增强模型抗投毒与对抗防御能力,提高AI的可靠性。花旗银行采用“对抗性数据增强”技术,在正常交易数据中注入10%的合成欺诈样本,迫使模型学习异常模式。经过10轮迭代训练后,其信用卡反欺诈模型的AUC-ROC值从0.82提升至0.93,对新型攻击的预警准确率提升41%。为防止数据投毒,瑞银集团在训练数据中添加“指纹标签”(Fingerprint Label),当模型在推理阶段检测到污染数据时,自动触发隔离机制,该技术使投毒攻击的成功概率从32%降至4%。
③鉴于AI模型幻觉的情况普遍存在,在应对AI模型可能产生“幻觉”输出方面,除需夯实可信数据基础、优化模型训练流程外,建立系统化的人工复核机制是确保输出准确性与可靠性的关键环节。该机制的核心在于,将人工智能的初步判断与人类专家的领域知识及最终决策权相结合,从而降低AI判断权重,进一步控制AI模型幻觉的错误率,形成有效的风险控制闭环。
具体而言,首先应依据业务影响与风险等级,对AI输出进行分级分类,明确界定必须触发人工复核的关键场景。例如,在涉及敏感客户风险评估或重大交易条款生成等高风险领域,模型的初始输出必须经由具备相应资质的专业人员审核确认后方可执行。其次,需为复核人员提供清晰、可操作的工作指引与辅助工具,例如通过可解释性AI技术高亮显示模型决策所依据的关键输入变量,或提供与历史案例的对比分析,以提升复核的效率与精准度。最终,所有人工复核的过程、依据及结论均需被完整记录,形成可追溯的审计线索,这既是对专业责任的明确,也为模型的持续优化与监管审查提供了不可或缺的数据基础。通过这种结构化的“人在环中”设计,能够有效拦截因模型幻觉导致的重大误判,在发挥技术效能的同时守住风险底线。
2、降低模型对历史数据的依赖
① 建立持续学习与动态更新机制,针对市场环境、监管政策或行业实践的突发性变化,建立模型的持续学习框架。采用增量学习技术,使模型能够在不遗忘已有知识的前提下,快速适应新的市场环境。例如,在场外衍生品相关模型中嵌入概念漂移检测模块,当检测到市场结构发生变化时,自动触发模型更新流程,确保模型始终反映最新市场状况。
② 引入市场机制理论与另类数据,减少对传统历史数据的过度依赖,通过引入市场机制理论和另类数据源增强模型的适应性。结合经济学第一性原理,将市场参与者的行为假设、供需关系等理论框架融入模型设计。同时拓展数据维度,引入新闻舆情、供应链信息等另类数据,提升模型在不同市场环境下的泛化能力。
③ 构建混合建模框架,采用"理论模型+AI校正"的混合建模方法。首先基于金融理论建立参数化模型,然后使用AI算法对模型残差进行校正。这种方法既保持了理论模型的可解释性,又利用了AI处理非线性的优势。例如,在场外衍生品估值中,先使用传统定价模型计算基础价值,再通过AI模型对流动性溢价、信用风险溢价等进行调整。
④ 强化压力测试与极端场景模拟,建立系统的压力测试框架,模拟各种极端市场场景,检验模型在训练数据分布之外的表现。通过对抗性样本生成技术,创造训练数据中未出现过但可能发生的市场情景,提升模型的鲁棒性。定期对模型进行样本外测试,确保其在市场环境发生结构性变化时仍能保持稳定性能。
策略趋同放大波动方面的应对
随着人工智能算法在场外衍生品交易与风险管理中的广泛应用,策略趋同问题日益凸显,已成为影响市场稳定的重要因素。由于多家市场参与者采用相似的数据源、模型架构和训练方法,导致其在市场波动时可能产生同质化交易行为,从而放大市场价格波动,尤其在流动性不足的场外衍生品市场,此类行为可能引发系统性风险。典型表现为在市场压力时期,多个机构的算法同时触发止损或对冲操作,加剧市场下跌。
当前主要痛点在于:一方面,算法策略的透明度不足,监管机构难以全面掌握市场的整体风险暴露;另一方面,模型与数据源的多样性欠缺,导致策略差异化程度较低。为应对这些挑战,主要采取以下方向:一是通过完善算法报备制度和交易监控机制提升市场透明度;二是通过监管激励和行业协作推动数据与模型的多元化发展。
▍提升场外衍生品市场的透明度及监控能力
增强市场透明度和监管监控能力是应对算法趋同风险的基础。欧盟MiFID II引入产品干预权力,要求算法交易报备(需描述策略逻辑与主要参数),提升透明度,便于监管机构评估市场整体风险暴露;美国证监会(SEC)Consolidated Audit Trail(CAT)全面追踪全美所有交易所的订单和交易,近乎实时监控,帮助识别异常交易行为(如由相似算法引发的集体行动),为监管提供数据基础。
我国可探索建立适用于场外衍生品市场的算法交易报告与评估机制,要求机构报告核心算法的逻辑、参数及潜在同质化风险,为监管机构识别系统性风险苗头提供数据支持。
立法规制方面,国际社会已在人工智能训练数据透明度层面提出明确要求。例如,2025年8月2日,欧盟《人工智能法案》(AI Act)中关于通用人工智能模型训练数据透明度的第53(1)(d)条条款正式生效。其配套的《通用人工智能模型训练内容公开摘要模板》也同时启用,首次要求将模型投放欧盟市场的通用人工智能模型提供者通过填写并公开摘要模板,披露AI模型训练数据的来源、处理方式等核心信息,否则可能面临高额罚款。欧盟《人工智能法案》规定:通用AI模型(包括开源模型)的提供者(下称“AI模型提供者”)既需要向“特定主体”公开,也需要向“全体公众”公开,公开内容分为三个部分:基本信息、数据处理相关信息,以及数据来源的清单。
美国则在训练数据透明度上亦进行了较多立法探索。在联邦层面,美国已有两部相关立法草案,分别为AI Foundation Model Transparency Act of 2023(下称“Act of 2023”)和Generative AI Copyright Disclosure Act of 2024(下称“Act of 2024”)。Act of 2023提出 “AI基础模型提供者”(covered entity that provides foundation model)除了将数据信息公开于自己的网站,还需同时提交给联邦贸易委员会(FTC),并公开于FTC建立的网站。AI基础模型提供者需要公开的具体内容可能包括训练数据的来源(如版权人或数据许可持有人维权所需的信息)、数据处理方式等。而Act of 2024则更加聚焦于对版权作品信息的公开,提出“创造或修改生成式AI模型训练数据集的人”(person who creates a training dataset, or alters a training dataset)需向美国版权局局长(Register of Copyrights)提交所使用版权作品“充分详细的摘要”(sufficiently detailed summary)以及链接。摘要和链接会发布于版权局局长建立和维护的公开在线数据库。
▍激励数据与模型多样性
除提升透明度外,鼓励数据和模型多样性是从源头降低策略同质化的重要途径。监管机构和行业组织可通过发布最佳实践、建立共享数据集、组织多样态算法竞赛等方式,引导机构开发差异化和互补性的交易与风控策略。
在监管激励方面,可考虑将模型多样性纳入金融机构风险管理能力的评价体系,对采用创新型、差异化AI策略的机构给予一定程度监管宽容或政策支持。行业组织也可推动建立跨机构的模型多样性指数,作为衡量市场韧性的参考指标之一,为市场参与者和监管机构提供前瞻性风险信号。
通过上述透明度提升和多样性激励的双重举措,可在一定程度上缓解因算法趋同而导致的波动放大问题,增强场外衍生品市场在面对极端行情时的整体稳定性和抗风险能力。
黑箱问题的风险应对
人工智能模型在场外衍生品定价、风险管理及交易决策中的深入应用,因其高度复杂的非线性结构而引发了显著的“黑箱”问题。该问题主要表现为模型决策过程不透明、输出结果难以追溯归因,进而带来三方面核心挑战:一是在监管合规层面,模型难以通过传统审计与验证流程,无法满足法规对模型可解释性与可审计性的要求;二是在风险控制层面,机构难以评估模型在极端市场情景(如流动性枯竭、波动率骤升)下的稳健性与可靠性,尤其对尾部风险的处理能力存疑;三是在业务操作层面,出现定价偏差或风险误判时,难以定位责任环节和关键特征,阻碍模型迭代与错误修正。
为系统应对上述挑战,需从技术增强与治理强化两个维度共同推进:在技术层面,引入可解释人工智能(XAI)技术提升模型决策过程的透明度;在管理层面,构建覆盖模型全生命周期的治理框架,确保AI系统的可靠性、可审计性与合规性。
▍采用可解释性AI技术
XAI技术旨在揭示复杂模型的决策机制,其方法可分为局部可解释性与全局可解释性两类。
局部可解释性理论根源来自于2012年诺贝尔经济学奖得主劳埃德·S·沙普利。SHAP(SHapley Additive exPlanations)旨在解释机器学习模型对于某个特定输入实例的预测结果 。它通过计算每个特征对预测结果的贡献度,来帮助我们理解为什么模型做出某个特定的决策,从而打开了机器学习的“黑盒”。它不仅揭示了特征影响的方向和强度,还能提供局部解释(Local Explanation),通过计算单个预测的SHAP值,对每一次预测进行详细的特征归因分析,用户可以理解模型为何对特定实例做出某个具体的预测。这使用户不仅能了解模型在整体上依赖哪些特征,还能具体分析某个特定样本的预测结果是如何由其各个特征值共同作用而产生的。LIME(Local Interpretable Model-Agnostic Explanations)技术首先确定需要解释的AI模型特定预测,再在选定预测的邻域生成略微改变的输入数据变体,接着记录模型对这些扰动样本的预测变化,并基于这些观察结果,创建一个简单的、可解释的模型,以模拟复杂模型在该局部区域的行为,最后提取关键特征:从简化模型中识别对该特定预测最具影响力的因素。
使用LIME(Local Interpretable Model-agnostic Explanations)或SHAP(SHapley Additive exPlanations)等技术局部可解释性分析,可分析某一笔特定衍生品交易(如利率互换、信用违约互换)中,哪些输入特征(如波动率曲面、期限结构、相关性假设等)对最终定价或风险价值(VaR)计算结果影响最大,并量化其贡献程度。这类方法尤其适用于前台交易和风控岗位的业务人员对特定交易决策进行事后审查与合理性验证。
全局可解释性则致力于理解模型的整体行为逻辑与依赖模式。通过聚合大量样本的SHAP值或采用基于规则的可解释模型(如决策树规则提取),可识别模型在不同市场环境下(如高波动regime、牛市/熊市状态)通常更关注哪些因子。例如,分析可能显示某深度学习定价模型在正常市场中主要依赖利率期限结构,而在压力时期则更多关注流动性溢价和对手方信用利差。
此外,通过反事实推理(Counterfactual Reasoning)构建“如果某个特征改变,预测结果将如何变化”的反事实样本,也能一定程度上应对黑盒相关挑战。根据已发生的事件或事实,假设与实际事件相反或不同的条件,最后基于假设条件推测出的可能结果。反事实推理的数学基础通常建立在因果图模型(CausalGraphicalModel,CGM)和概率论之上。在反事实推理中,我们通常需要计算在假设条件下的概率分布,即条件概率。如果我们想知道在某一假设条件X=x′X=x'X=x′下,结果YYY的期望值,我们会计算条件概率P(Y∣do(X=x′))P(Y|do(X=x'))P(Y∣do(X=x′))。
在实际应用中,反事实推理可以用于改进AI模型的可解释性和决策透明度。例如,在信贷审批决策中,假设AI模型拒绝了某笔贷款申请(X=0)并且该申请人最终在其他地方借款后发生了违约(Y=1),那么我们可以通过反事实推理问:“如果批准了这笔贷款申请(X=1)会怎样?”通过计算P(Y=1|do(X=1))(即计算在强制系统批准贷款条件下申请人发生违约的概率),我们可以评估模型原始决策的潜在影响。如果模型预测的P(Y=1|do(X=1))很高,说明拒绝决策避免了潜在违约损失,模型决策合理;如果该概率较低,则暗示模型可能错误拒绝了低风险申请人,错过了一笔良性贷款的机会。
尽管如此,现有方法仍存在局限。对于高度复杂或事关重大的金融决策,仅依靠事后解释可能并不充分。因此,部分机构开始探索“自解释模型”,如在模型设计阶段内置可解释性机制。代表性实践如中国工商银行开发的SEFraud系统——一种基于图神经网络的自解释欺诈检测框架。该系统通过可学习的特征掩码和边掩码,同步实现高精度欺诈检测与对检测结果的实时、自动解释,在保证AUC等性能指标提升的同时,其解释结果与业务专家的理解高度吻合,已成功应用于大规模在线交易监控场景。
▍构建透明与合规的治理框架
技术可解释性需与系统化的管理流程相结合,才能实现对“黑箱”风险的有效管控。这要求将AI模型纳入完整的模型风险管理(MRM)框架,实施严格的治理与控制。
一是,应建立全生命周期模型管理流程,涵盖模型的初始验证、持续监控与定期重检。在验证环节,除常规的精度指标外,须特别关注其在压力情景和样本外数据上的表现,评估其经济合理性和市场一致性。在投产后,应建立持续监控体系,跟踪模型性能衰减与概念漂移,并设定明确的模型重检与迭代触发机制。
二是,需贯彻全面的文档化与审计追踪原则。详细记录模型的设计理念、训练数据来源与预处理方法、特征工程、超参数设定、局限性以及关键决策日志,确保模型开发、部署与运行过程的可审计性。例如,摩根士丹利等机构推行的“模型护照”制度,要求为每个模型建立完整的档案,为内外部审计和监管检查提供便利。
客户隐私数据保护方面的风险应对
随着生成式人工智能在场外衍生品业务中的深入应用,客户隐私数据保护面临前所未有的挑战。场外衍生品业务涉及大量高敏感客户信息,包括客户身份、持仓明细、交易记录和风险暴露等,这些数据不仅受到《中华人民共和国网络安全法》《中华人民共和国个人信息保护法》等法律法规的严格保护,也直接关系到金融机构的商业机密和声誉风险。GenAI模型在训练和推理过程中需要访问大量数据,这一特性带来了三重核心痛点:一是数据泄露风险加剧,模型可能记忆并泄露训练数据中的敏感信息;二是权限管理复杂度提升,传统基于角色的访问控制机制难以适应AI模型的动态数据需求;三是合规压力增大,跨境数据流动、第三方数据共享等场景下的监管合规要求更为严格。针对这些挑战,当前主要从数据治理架构、技术防护体系和合规管理三个维度构建防护体系:通过建立完善的数据隔离与权限管理机制,确保数据最小化原则得到落实;采用隐私增强技术实现数据可用不可见;构建全生命周期的数据安全管理体系。
▍实施本地化部署与安全运营模式
为降低敏感数据外泄风险,金融机构应对GenAI系统实施本地化部署,将模型、数据及计算资源置于内部环境或受控的私有云中。例如,可通过与合规且具备强大安全能力的科技企业(如腾讯云、华为云等)以BTOB模式合作,构建专有云环境,确保所有客户数据、交易指令及风险模型不留存于第三方公有云。在此模式下,应关闭所有非必要的外部数据接口,对模型训练与推理任务实施严格的数据出口管控与实时审计,确保数据不离开金融机构的可信边界。
▍建立严格的信息隔离与权限控制机制
必须按照业务敏感性和合规要求,对数据进行分类分级,并建立相应的信息隔离机制。所有受保密协议约束、涉及个人隐私或第三方知识产权的数据,应通过数字标签、元数据标记等技术进行标识,并在输入AI模型前进行自动识别与过滤。在场外衍生品场景中,尤其需区分不同客户、不同业务线(如自营与代客)以及不同资产类别的数据,实施逻辑或物理隔离,防止数据越权访问或交叉使用。
▍加强生成数据的管理与合规使用
GenAI模型生成的数据(如合成数据、模拟交易、风险报告等)同样可能包含敏感信息或衍生商业秘密,也需纳入数据治理体系。应明确生成数据的归属、使用范围和访问权限,禁止直接用于模型再训练或对外共享,除非经过彻底的匿名化与脱敏处理。例如,利用生成数据训练新模型前,需通过差分隐私或k-匿名等技术处理,确保无法逆推出原始信息,并需通过合规与风险部门的评审。
▍实行客户数据分区与动态授权管理
针对GenAI查询和交互场景,应建立客户数据分区与动态权限控制机制。当模型访问公司内部数据接口时,系统需通过客户群组ID、交易角色和业务上下文实时判定数据权限,并强制实施行级或列级数据遮蔽。例如,当客户A通过智能客服系统查询其对手方B的潜在风险暴露时,系统应自动识别查询主体身份,若A无权获取B的头寸信息,则拒绝输出相关内容,并仅返回经模糊化或聚合处理后的风险提示。该机制尤其适用于场外衍生品这类高度依赖交易对手信用评估和风险关联管理的业务,可在提供智能化服务的同时严守客户保密义务。
通过以上多层次、体系化的技术与管理措施,金融机构能够在充分发挥GenAI业务价值的同时,有效保护客户隐私与商业机密,满足日益严格的数据合规要求。
▍构建纵深防御与技术治理体系
为系统应对网络攻击与隐私泄露风险,金融机构应构建融合技术措施与管理流程的纵深防御体系,并将安全与隐私保护要求嵌入系统全生命周期。该体系不仅包括基础的安全技术措施,更需强调主动防护与持续改进机制。
1、在系统设计阶段即遵循“安全与隐私设计(Security and Privacy by Design)”原则,将加密技术、身份认证与访问控制、网络防火墙及数据备份恢复等机制作为系统基础架构的核心组成部分。例如,对敏感数据实施端到端加密,结合多因素认证(MFA)与基于属性的访问控制(ABAC),确保数据在存储、传输及使用过程中均得到有效保护。
2、需建立持续性的安全监测与评估机制。定期开展网络安全渗透测试、隐私影响评估(PIA)及数据保护审计,全面检查系统中是否存在漏洞、配置缺陷或合规偏差。评估结果应用于持续优化安全策略和控制措施,确保其能够适应不断演变的威胁环境。
3、隐私增强技术(PETs)的创新为数据使用与隐私保护的平衡提供了新的解决路径。例如,基于对抗学习的隐私保护信用风险建模框架(PCAL)提出了一种新颖的思路:通过在客户端部署学习型掩码模型,对原始数据进行匿名化处理,在保证数据可用性的同时最大限度地减少隐私泄漏风险。该框架通过动态优化隐私保护与模型效用的平衡,为金融领域在高敏感数据环境中进行AI建模提供了可借鉴的实践。尽管PCAL最初应用于信贷领域,但其技术理念与方法同样适用于场外衍生品交易中的客户行为分析、风险预测等场景,体现了“数据可用不可见”的先进治理原则。
通过将强化的技术防护、持续的管理评估与创新的隐私计算技术相结合,金融机构能够构建一个既稳健又灵活的数据保护体系,有效应对GenAI应用带来的新型安全与隐私挑战。
AI大模型独有的安全风险
随着大语言模型在场外衍生品智能投顾、交易分析和合约生成等场景的加速落地,其特有的安全威胁逐渐显现,给金融机构的风险防控体系带来全新挑战。与传统AI系统相比,GenAI模型因其规模庞大、生成能力强且训练数据来源复杂,面临着三重独特威胁:一是新型攻击手段层出不穷,包括提示注入、模型逆向攻击和训练数据提取等,可能直接导致敏感业务信息泄露或模型被恶意操控;二是模型资产本身成为攻击目标,模型参数、提示词工程成果等核心知识产权面临窃取风险;三是服务稳定性威胁加剧,针对API接口的DDoS攻击可能造成交易系统瘫痪。这些风险在场外衍生品这一高风险领域尤为突出,可能引发连锁性市场波动甚至系统性风险。针对这些新型威胁,当前防护策略主要围绕三个方面展开:构建覆盖输入-推理-输出全链路的动态防御体系,强化模型资产本身的安全保护,以及提升服务架构的弹性恢复能力。
▍构建多层动态防御机制,防范恶意攻击
应对GenAI应用中的恶意攻击,需在系统各层级部署实时检测与防护措施。通过构建实时检测引擎,对输入指令进行语义分析与意图识别,能够有效识别提示注入、越权操作等恶意行为。在模型输入、推理与输出三个关键环节设置安全护栏,严格限制模型的操作权限,确保其无法直接执行资金划转、合约确认等敏感操作,所有关键指令需经由业务系统进行二次授权与复核。
国际领先机构已开展相关实践。例如,高盛集团建立“AI红队实验室”,系统性模拟147种MITRE ATLAS攻击框架中的技术,覆盖提示注入、模型逆向攻击及数据投毒等场景。在针对客户服务模型的攻防测试中,通过模拟“情感操纵”式提示(如“我急需资金周转,请优先处理我的额度申请”),成功识别原有策略漏洞,并优化了提示过滤与用户意图验证规则,将此类攻击的拦截率从65%显著提升至98%。在第三方模型管理方面,汇丰银行引入“模型护照”制度,要求模型供应商提供训练数据来源证明、对抗测试报告、伦理影响评估等12类合规材料,确保外部模型的可靠性与安全性,使供应商准入的不合格率从初期的45%降至18%。
▍实施分级加密与访问控制,保护模型资产安全
模型参数、提示词工程成果及微调数据是机构的核心数字资产,需实施严格的分类分级管理与访问控制。应对模型资产进行密级划分,核心参数与提示策略采用高强度加密算法进行存储与传输,并依托硬件安全模块(HSM)或可信执行环境(TEE)保护密钥与运行过程。同时,建立完善的访问审计日志,执行最小权限原则,确保仅授权人员可按需访问相应资源。
此外,应部署员工行为分析系统,通过机器学习监测异常访问模式,防范内部威胁。对物理基础设施同样需加强保护,对承载核心AI模型的服务器与数据中心实施生物识别访问控制、视频监控与入侵检测等物理安全措施,形成全方位防护。
▍设计弹性资源架构,防范服务中断风险
针对DDoS攻击与服务过载威胁,需构建弹性可扩展的资源架构。通过自动扩缩容机制,根据实时流量动态调整计算资源,以应对突发访问峰值。结合API限流、负载均衡与业务优先级调度技术,确保核心交易与风控业务在高负载下仍能稳定运行。
同时,可引入边缘计算节点,将部分计算任务分散至靠近用户的边缘节点执行,减轻中心模型服务压力。对高频且非实时的查询请求,启用缓存响应机制,提升响应速度并降低后端负载。通过这些技术措施,有效保障AI服务在高并发或遭受攻击时的持续稳定性,避免因服务中断引发的市场风险或操作风险。
监管立法
鉴于人工智能在各领域应用过程中产生的风险日益暴露及其影响的不断提升,境内外关于人工智能的监管立法逐步增多,且多国监管口径逐步趋于一致。代表性的事件包括:
1、2023年5月25日,新西兰信息专员办公室(OPC)发布《生成式人工智能指南》,指出生成式人工智能对新西兰公民个人信息的使用应遵守新西兰2020年《隐私法》;
2、2023年7月10日,中国网信办等七个部委联合发布《生成式人工智能服务管理暂行办法》,该办法明确规定其立法目的是促进生成式人工智能健康发展和规范应用;
3、2023年11月,英国召开AI安全峰会,28个国家发布《布莱切利宣言》推动全球在人工智能方面的合作,共同识别风险以制定跨国政策缓释风险;
4、2024年5月21日,欧盟理事会批准《人工智能法》,这一全球首部人工智能领域综合性监管法规遵循“基于风险”的方法,旨在规范人工智能的应用,侧重于制定与数据透明、分类分级监管和问责制度有关的规则,保护公民基本权利。该法在2024年8月2日正式生效。
5、2025年8月2日,欧盟《人工智能法案》(AI Act)中关于通用人工智能模型训练数据透明度的第53(1)(d)条条款正式生效。其配套的《通用人工智能模型训练内容公开摘要模板》也同时启用,相关法案要求人工智能模型提供者通过填写并公开摘要模板,披露AI模型训练数据的来源、处理方式等核心信息。此外,法案遵循“基于风险”的监管方法,将AI系统分为四个风险等级,并对应不同的监管要求。
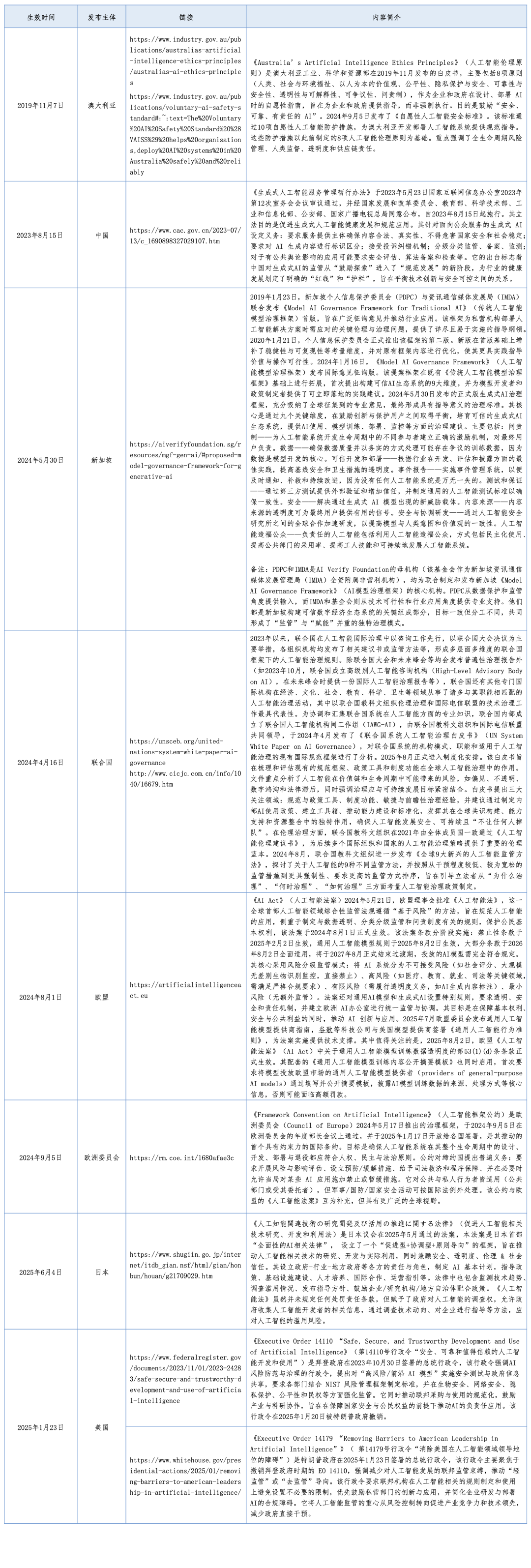
各国主要监管立法详见附录。
我们参考境内外相关人工智能立法规制,并结合人工智能在场外衍生品领域的应用实际,总结出人工智能在场外衍生品领域应用的立法建议:
分类分级监管框架:借鉴欧盟《人工智能法案》所倡导的‘基于风险’的监管范式,我国场外衍生品市场在推进AI应用时,可建立分类分级的监管框架。对于用于核心定价、风险管理和交易决策的AI系统,应参照‘高风险’系统标准,实施严格的全生命周期模型风险管理、强制性评估与人类监督;对于智能客服、文档处理等辅助性应用,则应侧重透明度披露。同时,应鼓励通过监管沙箱等机制,在风险可控的前提下支持创新,最终实现鼓励创新与防范风险的动态平衡。
数据隐私与质量规范:规范人工智能模型所依赖的数据,涵盖数据来源合法性、数据质量评估、数据保护措施等。要求金融机构使用合法获取的数据,建立数据质量评估体系,采取加密存储、访问控制等技术手段保护数据安全。
总结
本文研究表明,人工智能技术在场外衍生品领域的应用具有显著潜力,但其推广实施需采取审慎渐进的原则。尽管AI在提升交易效率、优化风险管理和创新产品设计等方面展现出独特价值,但受限于模型可解释性、数据依赖性及算法稳定性等内在特性,大规模深度应用仍面临实质性挑战。
现阶段建议采取分领域、分层次的推进策略。在智能客服、合同文档自动审核、客户尽职调查(KYC)及履约保证书处理等标准化程度较高、容错空间较大的业务环节,可优先开展规模化应用试点。这些领域不仅能够体现AI技术的效率优势,其相对可控的风险特征也符合稳健推进的原则。
而对于对冲策略优化、投资决策支持及市场预测分析等核心业务领域,则应坚持"试点先行、逐步深化"的实施路径。建议金融机构建立清晰的AI应用分级管理机制,重点强化模型风险管控体系,完善人工监督干预流程,确保在充分发挥AI技术优势的同时,有效防范潜在风险。
需要特别强调的是,场外衍生品市场由于其产品结构复杂、流动性相对不足、风险传导机制特殊等特点,对AI应用的稳定性、透明度和可靠性提出了更高要求。因此,在推进过程中必须始终将风险防控置于首位,通过建立完善的测试验证、持续监测和应急响应机制,确保AI系统的应用不会引发新的系统性风险。
未来,随着监管框架的持续完善、技术标准的逐步确立以及行业实践经验的不断积累,人工智能技术有望在场外衍生品领域发挥更加重要的作用。但这一进程必须建立在审慎规划、充分验证和有效监管的基础之上,以实现技术创新与风险控制的动态平衡。
附录:各国监管立法
往期回顾:
风险管理工具系列丨境内外场外衍生品业务中人工智能的主要应用场景
风险管理工具系列丨人工智能在场外衍生品领域应用的风险和监管挑战
【免责声明】本文信息仅用于投资者教育之目的,不构成对投资者的任何投资建议,投资者不应当以该等信息取代其独立判断或仅根据该等信息作出决策。本文信息力求准确可靠,但对这些信息的准确性或完整性不作保证,亦不对因使用该等信息而引发或可能引发的损失承担任何责任。
 北京市西城区闹市口大街1号院4号楼5层
北京市西城区闹市口大街1号院4号楼5层 电话:010-83897323 010-83897832
电话:010-83897323 010-83897832 邮箱:edu@csmonitor.cn
邮箱:edu@csmonitor.cn 邮编:100031
邮编:100031 意见反馈
意见反馈 投教联盟
投教联盟 免责声明
免责声明





